The Memory Supercycle: How AI Is Rewriting the Cycle
- Apr 14
- 18 min read
Updated: Apr 16
Writers: Abdur Raoup Mohammed, Charles-Olivier Plouffe

Editor’s note
To close out the scholar year, we wanted to take a slightly different approach. Until now, our work has mostly focused on individual companies and smaller-cap ideas. This time, we stepped back and covered an entire industry instead. Given how central AI has become to the market narrative, and how quickly memory has moved to the center of that buildout, the memory industry felt like the right place to end the year. In many ways, this piece reflects a shift in approach. We started small, focusing on single names, specific opportunities, and company-level stories. But as the market evolved, it became clear that some themes were simply too important to study one company at a time. Memory is one of them. It is one of the most important and most closely watched areas in the market today, not only because of the move in memory stocks, but because it sits at the heart of the AI infrastructure buildout.
TL; DR
Memory has always been one of the most cyclical corners of semiconductors, with demand booms usually ending in oversupply, margin compression, and sharp equity drawdowns.
This cycle looks different because the main driver is no longer phones or PCs, but AI, where compute is scaling faster than memory bandwidth and interconnect efficiency.
That has pushed HBM, inference demand, and data-center buildout to the center of the story, turning memory into one of the key bottlenecks in the AI stack.
The bottleneck is now feeding into a broader supply squeeze, as capacity is being redirected toward HBM and high-end server memory while the rest of the market gets tighter.
Suppliers are not rushing to eliminate the shortage, which may keep the market tighter for longer than in a traditional memory upcycle.
The key long-term question is whether memory eventually falls back into the old boom-bust pattern, or whether AI leaves the industry with a structurally higher floor for demand.
Part I: The old playbook
Memory chips are not just another semiconductor story
When people hear about AI, they usually think about the obvious names first. Microsoft. Nvidia. Google. The flashy side of the trade. But one of the most important industries sitting underneath all of this is memory.
And if you want to understand why memory names move the way they do, you first need to understand who really runs this market. The conversation still goes through three giants: Samsung, SK Hynix, and Micron. That matters because DRAM and NAND do not behave like some protected semiconductor niche with endless differentiation. They behave much more like a commodity market. When demand tightens, prices move fast. When supply catches up, prices can collapse just as fast. That is why memory has always been one of the most cyclical areas in semis.
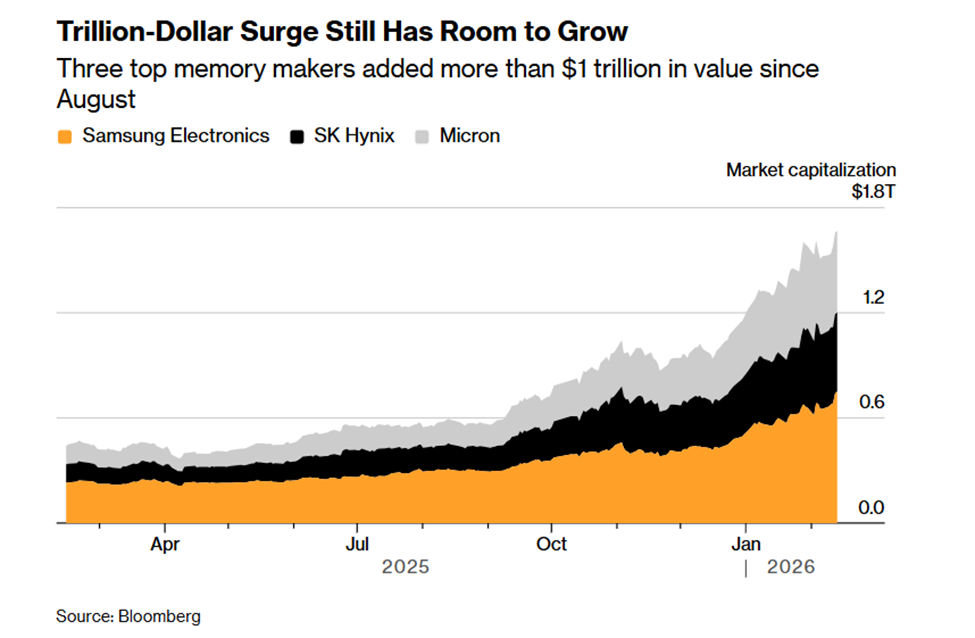
The market has already started to reflect that shift. As AI infrastructure spending accelerated, investors began re-rating the dominant memory manufacturers accordingly. The move has been broad enough to add more than a trillion dollars in combined value across Samsung, SK Hynix, and Micron, which shows that memory is no longer being treated as a background commodity story.
Why memory behaves like a hog cycle
The easiest way to explain memory is still the hog example. When hog prices go up, farmers get excited and start raising more hogs because they want to benefit from those high prices. But supply does not arrive overnight. It takes time before those hogs actually hit the market. In the meantime, prices stay high because demand is still stronger than supply. Then one day all that new supply finally shows up, demand has already cooled off, and now you have too much supply. Prices plunge.
Memory works the same way. When demand for DRAM and NAND surges, manufacturers rush to expand. They build fabs, add capacity, and try to capture the high pricing environment. But fabs take time. So, for a while, memory prices stay elevated because supply still cannot match demand. Then the new capacity finally lands, the shortage disappears, oversupply kicks in, and the cycle breaks. That is the basic memory script. It is not complicated. It is just brutal.
Why the boom always turns into a bust
This is exactly why memory investors are so paranoid all the time. They have seen this movie before. First, demand surges. Then pricing improves. Then margins explode. Then management teams start expanding. Then investors convince themselves that this time the good times will last longer. And then, as always, supply catches up, customers stop accepting higher prices, inventories build, and the stocks get hit before the financial statements fully show the damage.
That is what happened in the old cycles too. The 1993 to 1996 cycle was driven by the Windows PC boom and a jump in DRAM content per PC. The 2016 to 2019 cycle was driven by smartphone storage upgrades and early cloud buildout. Then the 2020 to 2023 cycle was pushed by the COVID work-from-home boom, with PCs, servers, and cloud demand all surging at once. Different trigger, same ending. Demand shock, capacity response, oversupply, collapse.
This pattern also matters for investors, because memory stocks tend to peak before the financials do. In the 2016 to 2019 cycle, Micron’s stock topped before revenue and margins reached their peak. That is exactly why the market is always so quick to price in the next downturn.
But the most important part is not the cycle itself
This is where most people get lazy. Yes, memory is cyclical. Everyone knows that. But that alone is not the real point. The real point is what is driving the demand this time. Because that is what tells you whether the old playbook still applies.
In past cycles, the big drivers were mostly the same old things. PCs. Smartphones. Cloud expansion. Device refreshes. Therefore, when phone makers started refusing higher prices, or when PC demand slowed, that was enough to make investors panic. And that is exactly what many are doing again now. They are seeing weakness in smartphones and acting as if the whole memory trade must be over.
That is the old framework. The real question is whether it still fits the current cycle. That is also why recent weakness in memory stocks should be read carefully. In a cyclical industry, the market is always looking for the first sign of rollover. But if the main driver has shifted from phones and PCs to AI infrastructure, then using the same old warning signals too mechanically may lead investors to call the turn too early.
Part II: Why this cycle looks different
This time the demand driver is completely different
The reason this cycle may be different is simple: the driver is no longer mainly phones or PCs. The driver is AI.
And not AI in some vague hype sense. I mean AI as an actual infrastructure problem. The key point is that AI compute has been growing much faster than memory bandwidth and interconnect efficiency. So the bottleneck is no longer just compute. The bottleneck is getting data in and out fast enough. That is the memory wall.

The difference becomes clearer when looking at how AI hardware has evolved. Compute performance has scaled much faster than both memory bandwidth and interconnect efficiency, creating a widening imbalance across the system. In other words, the bottleneck is no longer simply how much compute can be added. It is whether memory and data movement can keep up with it.
That is why this matters so much. If the old cycle was about end-device demand, this one is about memory becoming one of the core constraints on AI performance itself. That is a much more serious demand driver. And unless you believe AI spending is about to fall off a cliff, it makes no sense to look at weak phone demand and instantly conclude the entire cycle is finished.
What generative AI actually is
It is worth slowing down here and defining what we even mean by generative AI, because otherwise people throw the term around and move on.
Generative AI refers to models like ChatGPT, Claude, and Gemini, systems that generate text, code, images, and responses in real time. But what matters here is not the output. What matters is what is happening underneath. These models are built on huge datasets, large model weights, and enormous parameter counts, and they constantly need to process and retrieve information to function properly. From the start, this is already a much more memory-intensive source of demand than the usual phone or PC refresh cycle.
Why generative AI needs so much memory
Generative AI models are extremely memory hungry. During training, they repeatedly access massive datasets, parameters, and weights. And even after training, during inference, they still need to pull from memory constantly as they generate token after token. This is not a one-time demand surge where memory is only needed to build the model and then becomes irrelevant. Memory is needed both while training the model and while running it.
That is exactly why the current cycle looks different. In old cycles, memory demand was driven by devices people upgraded every few years. Here, demand is being driven by a whole new computing architecture in which memory is one of the factors limiting performance itself. If the AI ecosystem keeps scaling, memory demand does not simply disappear because some smartphone players decide they do not want to pay higher prices. That is no longer where the real pressure is coming from.
Why HBM becomes critical
Once you understand the bottleneck, HBM starts making perfect sense. HBM, or High Bandwidth Memory, is the memory solution built for exactly this type of AI workload. It stacks DRAM vertically, shortens the data-transfer path, and provides far more bandwidth than traditional memory. In plain terms, it moves more data, much faster, and that is exactly what these AI workloads need.
As large language models continue scaling, one chip is often no longer enough, so computation moves toward larger clusters of accelerators. And once that happens, the amount of data that has to move every second within the chip and across chips becomes massive. That is why HBM becomes one of the main ways to break through the memory wall.
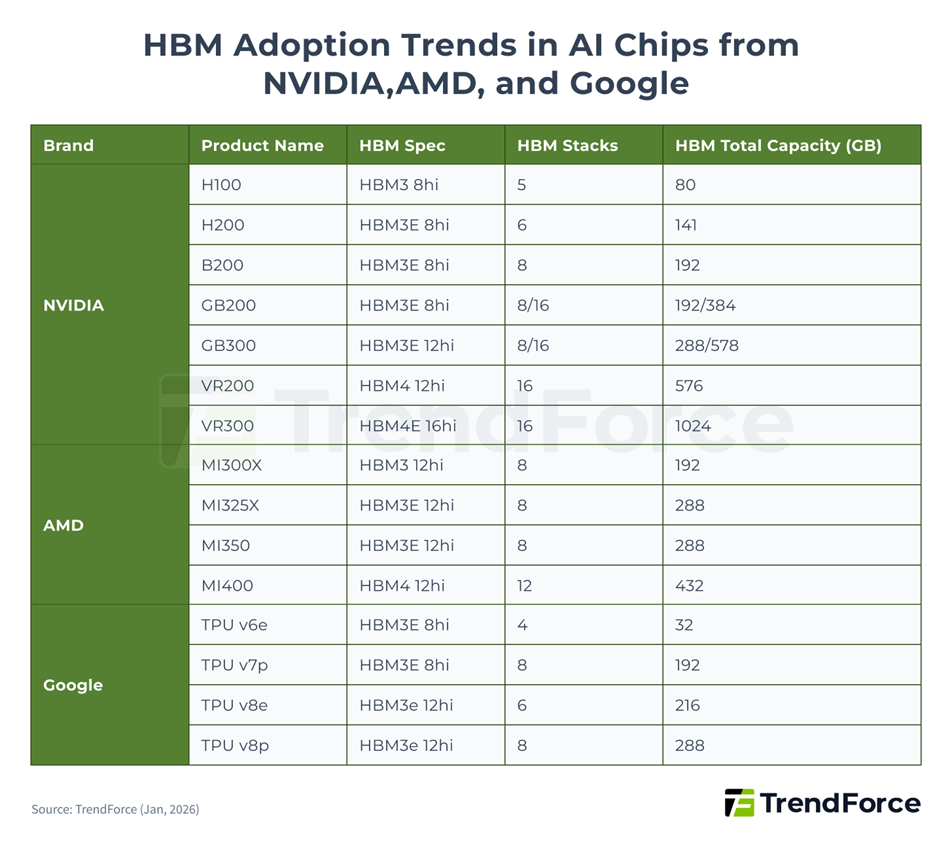
This is exactly why HBM has moved to the center of the AI memory story. As leading accelerators become more memory intensive with each generation, HBM is no longer a niche upgrade. It is becoming a core architectural requirement for the most advanced AI workloads.
And this is not just a theoretical story. It is already showing up in real product roadmaps. Nvidia, AMD, and Google are all moving toward newer HBM generations, with more HBM stacks and more total memory per chip. That directly pulls HBM demand higher. HBM is not a side story here. It is one of the clearest ways the AI buildout is translating into stronger memory demand.
And then the data center side makes the story even bigger
Even if someone understands why training needs memory, they can still miss what happens next. Because this does not stop at training. As AI shifts more toward inference, the demand broadens across the entire infrastructure stack. Once these models are deployed at scale, the story is no longer only about a few training clusters. It starts spreading across data centers, server deployments, networking architecture, and the broader infrastructure buildout.
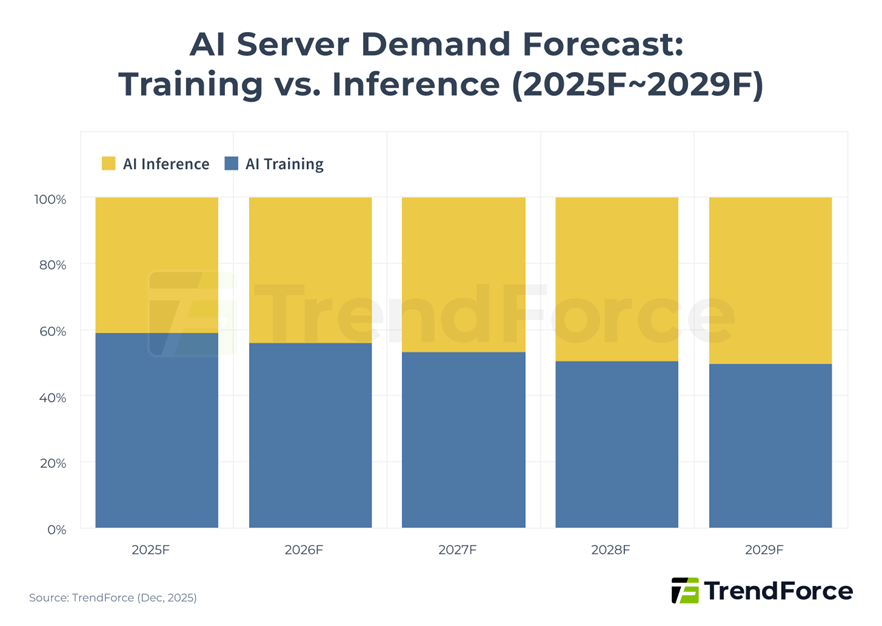
The story becomes even more important once AI moves from training into inference at scale. At that point, demand no longer stays concentrated in a small number of frontier clusters. It spreads across a much broader server base, which is exactly why the memory requirement becomes more durable and more system-wide over time. And once that happens, the memory story gets even wider. HBM matters for the hardest AI workloads, but it is not only about HBM anymore. Broader AI deployment also increases demand for server-grade DRAM such as DDR5. So, this is not just one narrow product cycle. It is multiple layers of the memory stack getting pulled higher by AI.
This is why it still feels early
The market keeps trying to call the top of the cycle, but the infrastructure wave still does not look fully built out. Hyperscalers are still accelerating capex, still expanding AI server fleets, and still deploying capital as though the demand opportunity remains in front of them rather than behind them. That matters because it suggests the memory story is still being driven by a buildout phase, not by a mature end market that is already starting to saturate.

That broader infrastructure push is also visible in capital allocation. The largest hyperscalers are not acting as though this is a short-lived theme. They are still accelerating investment into AI infrastructure, which reinforces the idea that the demand side of the memory story has not yet fully matured. The next question, then, is whether the industry can ease this bottleneck quickly enough to prevent it from becoming a broader market squeeze.
Part III: Why the bottleneck persists
Technical enablers
The problem was never just memory quantity
Even as AI pulls memory demand higher across multiple layers, the real constraint has never been only the amount of memory available. The deeper issue is how that memory is used. In traditional computing architectures, data must constantly move back and forth between the processor and memory banks. That movement consumes both time and energy, and as AI workloads become larger and more complex, it becomes one of the main limits on performance.
This is the memory wall in practical terms. For AI systems, especially large language models, the cost of moving data is increasingly becoming just as important as the cost of computing it. The industry therefore faced a clear choice: continue adding raw capacity or redesign the architecture itself. That redesign is now happening through both hardware and software.
Hardware is being redesigned to reduce data movement
One of the most important developments on the hardware side is processing-in-memory, or PIM. The idea is straightforward. Instead of repeatedly moving large amounts of data from memory to the processor for every calculation, part of the computation is performed closer to where the data already resides. By reducing this constant data movement, PIM lowers both latency and energy consumption.
That matters because AI workloads are dominated by the kind of matrix operations that suffer most from memory traffic. In that context, reducing movement is not just an incremental improvement. It directly improves the efficiency of the entire system. PIM matters not because it eliminates the need for more memory, but because it allows the industry to extract more useful work from the memory already in place.
Software is also changing the economics of memory
At the same time, software is becoming just as important in easing the pressure on memory. The basic unit of AI output is the token. Every word, every line of code, and every generated response depends on tokens, and the model must preserve context across those tokens to remain coherent. That is where the KV cache becomes critical. It stores the information needed for the model to remember prior context without recomputing everything from scratch. The problem is that this memory requirement grows quickly as context windows expand and as models begin handling more complex, multi-step tasks. Inference costs therefore rise not only because of computation, but because increasingly expensive memory must be reserved simply to maintain context.
This is where new software techniques become important. Compression methods, smarter memory management, and more selective use of model history can significantly improve how efficiently memory is used. The result is better utilization of the same hardware base and a lower effective cost per token.
This matters even more for the next phase of AI
These improvements become even more important as AI moves toward more agentic systems. A reliable agent is not just generating one answer. It must plan, retain context, reason across multiple steps, and remain coherent over longer interactions. That requires memory systems that are not only large, but efficient and persistent. Without better memory management, such systems would quickly become too expensive or too slow to deploy at scale. This is why hardware-software co-design matters so much. The model architecture, the compiler stack, the memory layout, and the hardware itself are increasingly being optimized together. That coordination improves performance, lowers cost, and allows larger models or longer contexts to run on the same infrastructure.
These advances do not weaken the thesis
Importantly, these technical advances do not reduce the importance of memory. If anything, they make the current tightness more sustainable. By improving efficiency, they make larger models more feasible, longer context windows more practical, and inference more economical. In other words, they help the system scale further. The effect is not to weaken the memory story, but to extend it. Even with those improvements, however, the market is still tight enough that the bottleneck is now moving from architecture into supply.
This is no longer just a demand story
The memory story is no longer only about rising AI demand. It is now about a bottleneck that is beginning to bind across the hardware stack. AI server demand and general server recovery have already pushed the market into shortage. The deeper issue is that AI compute scaling is outpacing improvements in memory bandwidth and interconnect efficiency, shifting the bottleneck away from raw compute and toward the memory subsystem itself, especially HBM.
The constraint is now hitting supply
That pressure cannot be resolved quickly. HBM demand is rising as AI accelerators move toward newer generations with more HBM stacks and greater total memory capacity per chip. At the same time, the three major DRAM manufacturers are allocating advanced process capacity toward HBM and high-end server DRAM, which limits supply for consumer DRAM. This is therefore no longer a normal upcycle in which demand rises, and supply eventually catches up smoothly. AI is pulling the market in one direction, while the rest of the memory ecosystem is being squeezed.
This is where the real squeeze begins
That is what turns stronger AI demand into a genuine supply shock. HBM and high-end server DRAM offer the strongest economics, giving manufacturers a clear incentive to direct more advanced capacity toward AI-related products. But capacity is finite. As more of it is redirected toward HBM and server memory, less remains available for consumer and general-purpose DRAM. Demand is not merely growing in isolation. It is absorbing limited capacity and tightening the rest of the memory market.
The spillover is already visible
The effects are already showing up downstream. The shortage is pushing overall memory prices higher and beginning to pressure device economics. Smartphones, laptops, and gaming systems are already feeling the impact through higher memory costs, lower specifications, and weaker shipment expectations. At that point, this is no longer just an AI niche story. It has become a broader supply-demand squeeze spreading across the entire memory ecosystem.

The squeeze is no longer confined to high-end AI hardware. Once capacity gets redirected toward HBM and high-end server DRAM, the effect starts spreading into standard DRAM and NAND as well, pushing prices higher across multiple categories. At that point, the supply shock is no longer theoretical. It is showing up across the broader memory stack.
Suppliers are not rushing to eliminate the shortage
This is the second point the market may be underestimating. In a normal memory cycle, once prices rise enough, suppliers rush to close the gap. That is often what eventually destroys pricing and margins. This time, the response appears more measured. Producers are allocating more advanced capacity toward HBM and high-end server DRAM, which keeps supply tighter for lower-end memory and limits how quickly the shortage can disappear. What makes this different from a textbook memory cycle is that the industry is not racing to eliminate scarcity as quickly as possible. New capacity will take time to arrive, and in the meantime, suppliers have strong incentives to preserve pricing discipline, prioritize hyperscalers and large OEMs, and let the market remain tighter than it would have in a more traditional upcycle. The point is not that cyclicality has disappeared. It has not.
The point is that suppliers are not behaving as though they intend to flood the market immediately and crush pricing. They are moving more cautiously, protecting margins, and prioritizing the customers that matter most. That makes the current tightness more durable and slows the pace at which the market can normalize. None of this means the path will be clean. Even if the long-term setup remains strong, the Supercycle still faces meaningful risks.
Part IV: What could go wrong
Risks
The bull case is strong, but not bulletproof
Even if the long-term setup remains strong, this Supercycle is not some perfect straight line up. There are real headwinds here, especially once you move beyond the hyperscalers and look at the rest of the ecosystem. Long-term agreements, software optimization, and newer memory architectures can help absorb part of the pressure, but they do not make the cycle untouchable. At best, they make it harder to break. The real question is whether the broader AI rollout can keep moving at the same pace once you leave the biggest tech firms behind.
The whole chain is more fragile than it looks
One of the biggest problems is how concentrated everything still is. Advanced memory production remains heavily concentrated in South Korea through Samsung and SK Hynix, while Taiwan stays critical for advanced packaging. That means the system works well when everything is calm, but it becomes fragile the moment geopolitics starts heating up. Tensions around Taiwan, energy shocks hitting Korean fabs, or disruptions in key materials can all hit the chain at once. The industry looks powerful, but it is also sitting on top of a great deal of geographic concentration risk.
Politics can slow what demand wants to accelerate
Then there is the policy side, which matters more than many people think. Even when chips are produced outside the United States, the manufacturing process still depends heavily on U.S.-origin equipment, software, and technology. That gives Washington more control over the global memory chain than many investors want to admit. Export controls do not just affect who gets chips. They affect where companies can expand, how confident they feel when investing, and how smoothly new capacity can come online. So even if demand stays hot, policy can still distort how fast supply responds.
What helps hyperscalers can squeeze everyone else
Another major risk is what happens when too much capacity gets redirected toward HBM. That is great for hyperscalers, but not so great for the rest of the market. Once more manufacturing goes toward HBM, legacy DRAM and NAND get tighter, and prices start moving up hard. That cost pressure does not stay inside the AI trade. It spills over into smartphones, PCs, gaming consoles, and edge devices. Suddenly the pressure spreads across the rest of the market too.
The risk is not necessarily collapse. It is narrowing
And that is probably the cleaner way to think about it. The Supercycle does not need to collapse for the market to run into trouble. It can simply become narrower. Hyperscalers keep locking in supply, keep building, and keep absorbing higher costs, while smaller firms, consumer devices, and edge AI deployments get squeezed out. That would not kill the thesis. But it could absolutely slow the pace of broader AI adoption outside the few firms with the deepest pockets. That tension matters because it pushes the debate beyond the immediate shortage and toward a larger question: what kind of market structure emerges once the first wave of AI buildout begins to normalize?
Part V: What comes after
Future scenarios
The more important question begins after the first wave
Looking beyond the immediate Supercycle, the more important question is not whether demand stays strong next quarter. It is whether advanced memory demand settles back into the old boom-bust pattern once new capacity comes online, or whether AI leaves the industry with a structurally higher floor.
At the moment, the second possibility is becoming harder to dismiss. Even as additional fabrication capacity is gradually added, the underlying evolution of AI applications suggests that demand for advanced memory could remain elevated well into the next decade. Technical enablers such as processing-in-memory and more sophisticated token-management techniques should help mitigate some of the bottlenecks. But mitigation is not the same as elimination. The emerging use cases still point toward rising requirements for high-bandwidth, low-latency memory.
The next phase of AI is even more memory intensive
That becomes clearer when looking at where AI is headed next. Agentic systems, and eventually more advanced forms of AI, will place heavier demands on memory architectures than today’s mainstream workloads. Autonomous vehicles require real-time sensor fusion and long-horizon reasoning over large amounts of contextual data. Humanoid and industrial robotics depend on persistent memory to remain coherent across extended interactions and physical tasks. Personal and self-hosted AI systems point toward localized, privacy-sensitive agents with longer context windows and more continuous interaction.
In each of these cases, the issue is not simply greater memory capacity. It is the need for reliable performance built on low-latency access to memory that can support multi-step reasoning over longer periods of time. As AI becomes more embedded in real-world systems, the quality and responsiveness of memory matter just as much as the amount of it.
Efficiency may broaden the market rather than relieve it
There is also a second dynamic that matters here. Efficiency improvements do not necessarily reduce demand. In many cases, they do the opposite. This is where the Jevons paradox becomes relevant. As hardware-software co-design improves token economics and lowers the cost of deploying more advanced models, the result may not be lower aggregate demand for memory. Lower costs can encourage broader experimentation, longer context windows, more complex models, and wider deployment across industries. In other words, the same innovations that ease bottlenecks at the system level may simultaneously expand the market using that system.
That is why technical progress should not automatically be read as a bearish signal for memory demand. If AI becomes cheaper and easier to deploy, the demand base may broaden enough to offset a large part of those efficiency gains.
Normalization may come, but a full reset is less certain
Of course, some normalization remains plausible. By 2028 and beyond, as new facilities from Samsung, SK Hynix, and Micron reach volume production, the supply side should look healthier than it does today.
But healthier supply does not automatically imply a return to the old baseline. HBM consumes significantly more capacity per bit than traditional memory, and AI is becoming more deeply integrated into physical systems, enterprise workflows, and everyday computing. That combination suggests the Supercycle may evolve into a higher baseline rather than simply revert to the classic memory pattern investors are used to.
So, the key question is not whether the current tightness lasts forever. It almost certainly does not. The more important question is whether the industry settles into a structurally higher level of demand than in prior cycles. That outcome now looks increasingly plausible.
Memory may define the limits of the next AI wave
Ultimately, memory is emerging as both a natural constraint and a critical enabler of AI progress. Its trajectory will influence how quickly advanced AI systems can scale, how widely they can be deployed, and which applications become economically viable. Continued innovation in system architecture, memory management, and hardware-software integration will therefore remain essential. The next phase of AI will not be determined by compute alone. It will also depend on whether memory can keep pace with the demands placed on it.
Disclosures
This document has been produced by Marchés Globaux HEC (“MGH”) strictly for academic and informational use. The views, forecasts, and assessments presented are derived from publicly accessible sources that are believed to be accurate at the time of preparation; however, MGH has not conducted any independent verification of such data. Nothing in this document should be interpreted as investment advice, a solicitation, or a recommendation to buy, sell, or hold securities, nor as a valuation or professional opinion under Canadian or other applicable regulations.
MGH operates as a student-led initiative. Its authors are not registered financial advisors, legal experts, or accounting professionals, and the content herein is provided solely to foster discussion and learning. This material is intended exclusively for educational purposes and may not be copied, quoted, or distributed in whole or in part without prior written approval from MGH.
Rédigé par l'équipe d'Equity Research


